History of machine translation
- Early days
The origins of translation machines date back to the 1930s. That is when, in 1933, an engineer Georges Artsrouni patented the first translation machine in history - his electronic multilingual dictionary called “mechanical brain”. The device could print information and perform translations by replacing one word with another.

Artsrouni's invention [1]
Another scientist who worked on a similar invention at the same time was Petr Troyanskii. He created a translation device consisting of an inclined desk and a belt with protrusions moving along several axes. The belt was a large dictionary containing terms in six languages. To use this device, the operator had to select a word from the source language and scroll to find a substitute in another language. Troyanskii’s invention was a breakthrough in automatic translations.
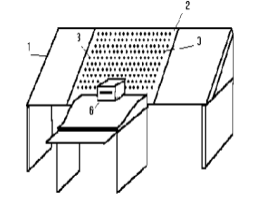
Troyanskii's invention [2]
- 1950s-1970s
In 1954 the widely reported Georgetown-IBM experiment took place. The aim of it was to demonstrate the capabilities of machine translation. For this purpose, the IBM researchers typed sentences in Russian language and translated them into English using an IBM 701 computer. It was a small-scale experiment - the computer had a system consisting of 250 words and 6 grammar rules, yet it gave hope that in the nearest future it would be possible to translate texts fully automatically. As a result of the performance, the government decided to invest in the development of computer linguistics. However, as history has shown, the process of creating the perfectly usable machine translation tool was a lot slower than expected.

Machine translation demonstration [3]
Despite all the efforts put into developing the new technology, the output generated by the first machine translation systems contained many errors and allowed only a cursory understanding of the translated texts.
Due to the unsatisfactory results, the American government decided to convene ALPAC (Automatic Language Processing Advisory Committee) to evaluate the progress. ALPAC published a report which stated that machine translators were very expensive and there were too many errors in their output.
Despite the failures, the demand for machine translators continued to increase. Most users were ready to accept the poor-quality output for the sake of easy access to information. Some of the popular systems in those days include:
- The METEO system (1954) capable of translating weather forecasts from English to French
- The Mark II (1957) installed at the USAF Foreign Technology Division
- Systran (1968) used by United States Air Force to translate Russian scientific articles into English
- Logos (1960s-1970s) developed to translate Russian military documents into English
- 1980s-1990s
The 1980s and 1990s saw a diversity of approaches with researchers exploring different methods. Rule-based systems (relying on linguistic rules and dictionaries) were still frequently used, while statistical models (learning from parallel corpora) began to gain popularity. The important development of machine translation was driven by the increasing adoption of personal computers that gradually replaced mainframe machines. With the popularity of PCs, translation software transitioned from primarily serving translators to becoming accessible for everyone. This change led to the start of online translation services, such as:
- Babel Fish
- Systran
- FreeTranslation.com
- WorldLingo
- 2000s-2020s
In the 2000s, statistical machine translation systems completely replaced the rule-based models. Siginificant advancements were made in speech translation, leading to the creation of many solutions for translating parliamentary speeches and news broadcasts. This era also witnessed the expansion of MT into various domains such as TV subtitles, restaurant menus or websites.
The following decade brought about a revolutionary technology: neural machine translation (NMT), which supplanted statistical MT. First introduced in 2010, NMT went through several years of research before being launched by Baidu. Google followed suit in 2016 by transitioning from its main statistical MT engine to adapt the new NMT model. In 2017, the Transformer model was introduced. It showed superior performance compared to earlier versions. Since then, researchers have been training increasingly larger language models, such as BERT and GPT (Generative Pre-trained Transformer) on large amounts of text data. This has resulted in strong performance across many language tasks, including generation, comprehension and translation.
There has also been a growing interest in multilingual and zero-shot translation. Advanced models are trained to translate between different language pairs without going through a language-specific training. It means that a single model can translate between multiple languages with minimal or no additional training data.
Machine translation continues to be a subject of research, with a focus on improving models, training methodologies and optimization techniques. These efforts contribute to advancements in translation quality and efficiency.